|
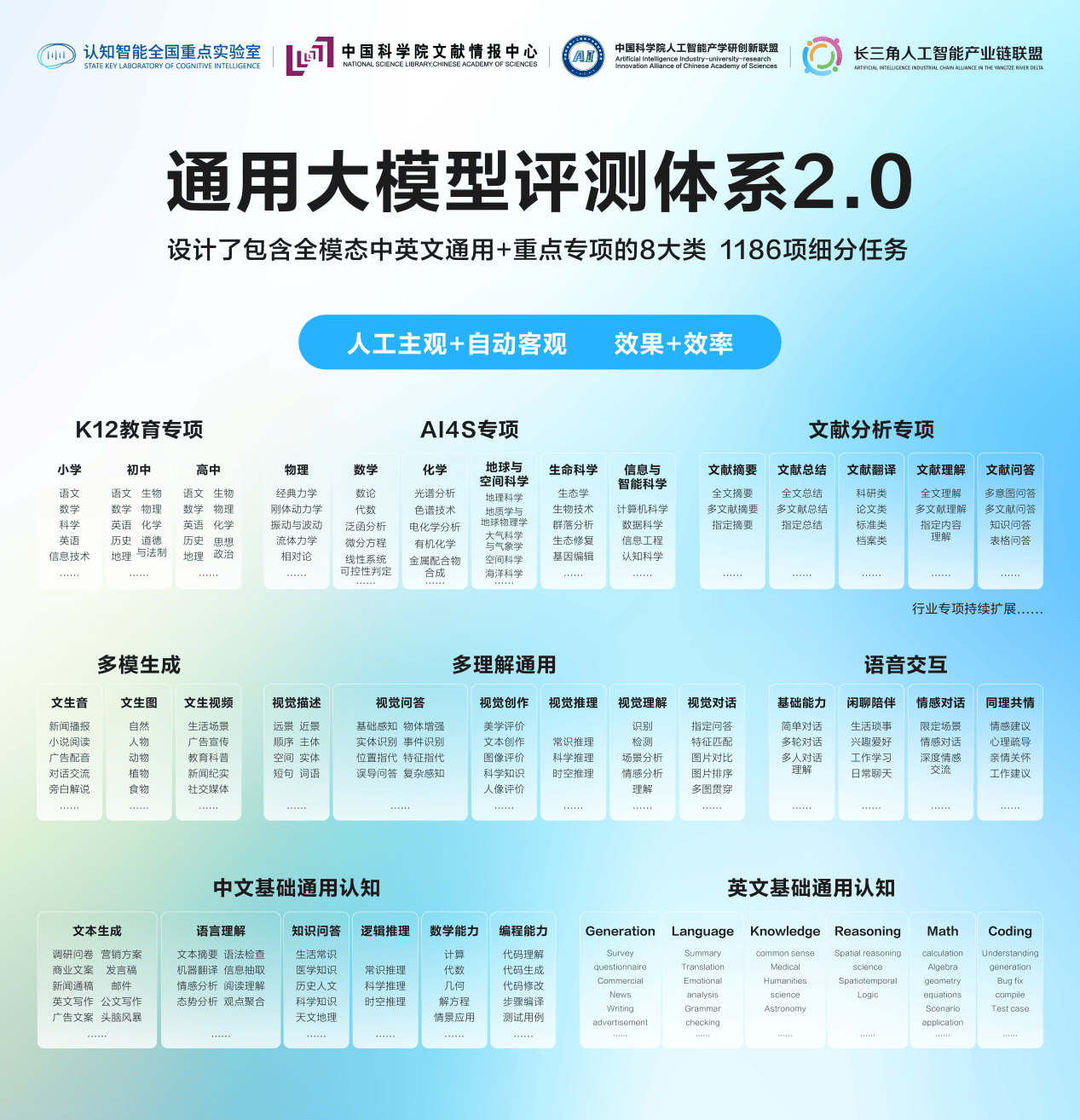
6月24日,认知智能全国重点实验室牵头,联合中国科学院文献情报中心、中国科学院人工智能产学研创新联盟、长三角人工智能产业链联盟发布《通用大模型评测体系2.0》。
相比2023年6月发布的1.0版本,此次升级发布的2.0版本以产业需求为导向,在评测维度扩展、专项能力深化、评测方法优化等方面实现突破。 在评测规模上,评测任务从原来的481项大幅扩展至1186项,评测模态从单一的文本、图片扩展到文本、图片、语音、视频的全模态覆盖。在语言支持方面,新版评测体系从以中文为主调整为中英文并重,更好地适应大模型国际化发展趋势。 新升级的评测体系以行业场景需求为锚点,新增教育、科研等重点专项评测领域,构建起技术与产业深度融合的价值验证桥梁:面向教育行业,覆盖K12教育领域的多学科知识能力测评,从智能备课内容生成的教学场景到个性化学习路径规划的辅学场景,通过标准化评测对模型进行能力验证,驱动大模型在因材施教、智能辅导、教学质量评估等核心应用场景的产业化落地;面向科研行业,AI4S(AI for Science)专项涵盖了物理、数学、化学、地球与空间科学、生命科学、信息与智能科学等6大科学领域,覆盖98项细分任务场景。 为确保评测质量,“评测体系2.0”建立了严格的数据构建准则,在确保数据高质量的准则下进行构建:通用任务测试采用来源、题型、类别等多样性采样机制,确保数据真实性和多样性;专项任务测试数据在规范性、可用性、可解释性、合规性4个方面15个子维度进行严格质量把控。在评测方法上,采用“人工+自动”结合模式,以多人主观双盲评测为主,JudgeModel(判断模型)为辅;并建立了“1+4”评价体系,即总体评分加上相关度、连贯度、完整度、有效度四个维度的细分评价。 此外,新版评测体系还特别强化了安全评测,设计了16项风险指标,涵盖内容安全和指令安全两大类别。这一设置契合了当下行业对AI应用安全重视程度不断提升的趋势,为大模型安全部署提供重要保障。 (责任编辑:郭健东 )
【免责声明】本文仅代表作者本人观点,与和讯网无关。和讯网站对文中陈述、观点判断保持中立,不对所包含内容的准确性、可靠性或完整性提供任何明示或暗示的保证。请读者仅作参考,并请自行承担全部责任。邮箱:news_center@staff.hexun.com |