|
凤凰网科技讯 7月4日,阿里通义实验室宣布开源首个音频生成模型ThinkSound。该模型首次将思维链(CoT)技术应用于音频生成领域,旨在解决现有视频转音频(V2A)技术对画面动态细节和事件逻辑理解不足的问题。 根据通义语音团队介绍,传统V2A技术常难以精确捕捉视觉与声音的时空关联,导致生成音频与画面关键事件错位。ThinkSound通过引入结构化推理机制,模仿人类音效师的分析过程:首先理解视频整体画面与场景语义,再聚焦具体声源对象,最后响应用户编辑指令,逐步生成高保真且同步的音频。
图源:通义大模型微信公众号 为训练模型,团队构建了首个支持链式推理的多模态音频数据集AudioCoT,包含超2531小时高质量样本,覆盖丰富场景,并设计了面向交互编辑的对象级和指令级数据。ThinkSound由一个多模态大语言模型(负责“思考”推理链)和一个统一音频生成模型(负责“输出”声音)组成。
ThinkSound 音频生成模型的工作流 据悉,ThinkSound在多项权威测试中表现优于现有主流方法。该模型现已开源,开发者可在GitHub、Hugging Face、魔搭社区获取代码和模型。未来将拓展其在游戏、VR/AR等沉浸式场景的应用。 以下附上开源地址: https://github.com/FunAudioLLM/ThinkSound https://huggingface.co/spaces/FunAudioLLM/ThinkSound https://www.modelscope.cn/studios/iic/ThinkSound (责任编辑:张晓波 )
【免责声明】本文仅代表作者本人观点,与和讯网无关。和讯网站对文中陈述、观点判断保持中立,不对所包含内容的准确性、可靠性或完整性提供任何明示或暗示的保证。请读者仅作参考,并请自行承担全部责任。邮箱:news_center@staff.hexun.com |


1 小时前

1 小时前

1 小时前

1 小时前


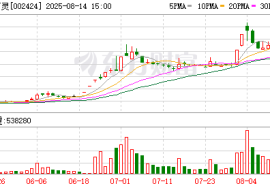
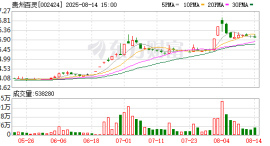
“苗药第一股”贵州百灵风波不断。 12月19日晚间,贵州百灵企业集团制药股份有

2025年收官在即,全年针对证券业的监管罚单已披露七七八八,监管框架全景图清晰成

12月20日,全球首台商用超临界二氧化碳发电机组在贵州六盘水首钢水钢集团成功商运

每经记者|高涵每经编辑|王嘉琦 AI手机的技术路线已形成鲜明分野。12月19日,字节

每经记者|赵雯琪每经编辑|魏文艺 在迪拜、香港商业化运营后,美团无人机再迎新进
每经记者|张宝莲每经编辑|文多 昔日合作伙伴,如今要对簿公堂。12月19日,科创板

每经记者|黄鑫磊每经编辑|许绍航 文多 2025年12月19日,*ST围海(SZ002586,股价

美军,突然动手! 据最新消息,当地时间12月19日,美国军方对叙利亚境内极端组

近期,证券时报记者走访多地发现,以宠物主题乐园、宠物出行为代表的新消费场景热

据央视新闻12月20日消息,当地时间12月19日,美国司法部开始公布爱泼斯坦案相关的