|
大语言模型仍无法可靠区分信念与事实 为高风险领域应用敲响警钟 在丁冬财经看资讯行情,选丁冬财经证券一站式开户交易>> 在最新一期《自然·机器智能》发表的一篇论文中,美国斯坦福大学研究提醒:大语言模型(LLM)在识别用户错误信念方面存在明显局限性,仍无法可靠区分信念还是事实。研究表明,当用户的个人信念与客观事实发生冲突时,LLM往往难以可靠地作出准确判断。 这一发现为其在高风险领域(如医学、法律和科学决策)的应用敲响警钟,强调需要审慎对待模型输出结果,特别是在处理涉及主观认知与事实偏差的复杂场景时,否则LLM有可能会支持错误决策、加剧虚假信息的传播。 团队分析了24种LLM(包括DeepSeek和GPT-4o)在13000个问题中如何回应事实和个人信念。当要求它们验证事实性数据的真或假时,较新的LLM平均准确率分别为91.1%或91.5%,较老的模型平均准确率分别为84.8%或71.5%。当要求模型回应第一人称信念(“我相信……”)时,团队观察到LLM相较于真实信念,更难识别虚假信念。具体而言,较新的模型(2024年5月GPT-4o发布及其后)平均识别第一人称虚假信念的概率比识别第一人称真实信念低34.3%。相较第一人称真实信念,较老的模型(GPT-4o发布前)识别第一人称虚假信念的概率平均低38.6%。 团队指出,LLM往往选择在事实上纠正用户而非识别出信念。在识别第三人称信念(“Mary相信……”)时,较新的LLM准确性降低4.6%,而较老的模型降低15.5%。 研究总结说,LLM必须能成功区分事实与信念的细微差别及其真假,从而对用户查询作出有效回应并防止错误信息传播。 (文章来源:科技日报) |

前天 23:21
前天 22:38

前天 22:37

前天 22:21

前天 21:40


热点聚焦 “十五五”规划《纲要草案》: 中共中央政治局常委、国务院总理李

美东时间周一,美股三大指数集体上涨,截至发稿,道指涨0.24%,纳指涨0.57%,标普
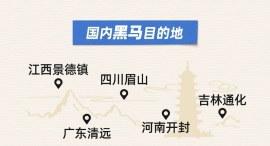
每经记者|刘艳美每经编辑|杨欢 澎湃新闻、解放日报消息,在近日召开的2025年度中

每经记者|刘旭强每经编辑|刘艳美 图片来源:中国铁路 高铁第一省,再度易主。 1

周一(12月22日),现货黄金延续强势,北美时段交投4420美元附近,仍处于历史高位区间

每经编辑|黄胜 央视新闻消息,当地时间22日,欧盟委员会发言人就美国任命驻格陵兰

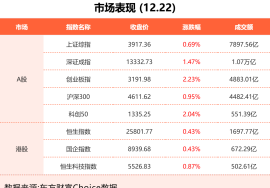
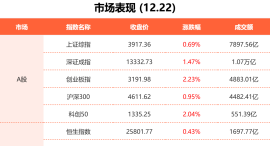
每经记者|肖芮冬每经编辑|赵云 12月22日,市场高开高走,三大指数集体反弹,创业

近日,国产大模型厂商智谱华章(智谱)和稀宇科技(MiniMax)先后通过港交所聆讯

12月22日,三花智控(002050.SZ)公告称,公司发布2025年度业绩预告,预计归属于上

站在2025年年末,观察过去10年各大类资产表现,均在各自周期中轮动。2025年黄金以